

Goals And Methods In Statistics & Machine Learning
How We Are Thinking About Statistics Today


Above is an excerpt from Keynes’ A Treatise On Probability. In this short passage, Keynes proves Bayes’ Theorem from an equational structure on multiplying probabilities for the first time in history. Keynes motivated those equations with a theory of still logical but merely probable inference. Keynes method of proving of Bayes’ theorem is what gives the idea its modern importance. But for what blasted reason did Keynes develop a whole theory of probable inference in the first place?
“But, of course, the real test of any new principle in science is not its ability to re-derive known results, but its ability to give new results, which could not be (or at least, had not been) derived without it.”
Edwin Jaynes, Probability: The Logic Of Science, Chapter 30: ‘Maximum Entropy: Matrix Formulation’.
This question is related to one of the recurring questions we have had: “Is philosophy about forming a Socratic dialectic with one’s cultural endowment or about sharply defined intuition gadgets?”. We have frequently used probability theory as a place to investigate this question. In addition to Keynes, one might wonder where Kolmogorov, Cox and de Finetti fit into all this. Indeed, how can our dialectic be precise without axiomata and the resulting deductive structure?
This question represents a certain view on the foundations of science. The name “foundations” suggests a hard place on which structures can be constructed, like Kirkcaldy. The foundations of a building are laid first and those foundations are never disturbed lest the structure whole and entire must fall down. This instability is rather unlike Kirkcaldy, as far as I know.
In certain old ways of thinking (I have never been able to find exactly who holds this oft refuted doctrine), all that is necessary in the foundations of science is the true meanings of the technical words: from the nature of a triangle, conclude that the sum of the angles must sum to two right angles. Devastating criticisms of this point of view are contained in Kritik der reinen Vernunft, Πυῤῥώνειοι ὑποτυπώσεις, वज्रच्छेदिकाप्रज्ञापारमितासूत्र, Πολιτεία and 莊子, to name an arbitrary handful of old books.
This is not to say the dialectical method is necessarily historical. I recall some classicist arguing that the original Euclid had no postulates himself, and one of the points of the book was to reconstruct what the postulates would have to be (much like Book XI, which has 25 definitions but no postulates for solid geometry). That would be an example of a deductive dialectic which is not historical.
As those critics and classicists suggest, Kirckaldy manages to get things done in a more stable manner. So, I believe this view of ‘foundations as foundation’ is incorrect. Instead, I hold that the foundations of a science are the part of that science where that field itself is the positive domain, though the foundational theories may be positive or normative. In the foundations of mathematics, the subject is mathematics itself: can mathematics be proven or at least suggested? The aim of the foundations of statistics, then, is to see if statistics can be proven or at least suggested.
As Jaynes said, success is when that proof or suggestion is and provides something beyond previously observed statistical methods into new statistical methods. As we shall see, the questions our approach raises apply to machine learning as well as traditional statistics.
Thus I see, for example, Kolmogorov’s pamphlet more like a lamp than a pyramid. Kolmogorov’s axioms of probability are tested immediately by whether they can successfully hold up the important relations of probability - Bayes Theorem, Independence and Conditional Independence - and are tested again in a mediated way by the fact their interpretation in a space with finite Lebesgue measure allowed for the discovery of new statistical methods. The research program of Kolmogorov’s axioms are, in this way, justified by their success.
Let’s take one example. Kolmogorov had a structural theory of the notion of independent experiments. By structural, I mean that the theory is developed using a recursive system of equations without regard to their real world interpretation. The structure itself was abstracted from existing statistical practice. The idea of independent experiments did not burst into the world virginally from the skull of Kolmogorov!
To name just one example of how independence was used in statistics before Kolmogorov, Airy had treated independent and entangled (i.e. nonindependent) observations in his book Errors Of Observations. Airy gives the example of two reports on the transit of the moon, one from observatories a and b and the second from observatories b and c. The probable error in each report is (related to) the sum of the probable errors from each observatory’s data, but the total probable error is not the sum of four probable errors. Thus he sees entanglement (and, by implication, independence) not as structural, but substantive.
Still, Kolmogorov’s structural theory of independence has been successful in Jaynes’ sense. Its formalizations have been seen to be useful for information theory (see Kolmogorov’s “The Theory Of Transmission Of Information” ), population genetics (see Kolmogorov’s “Solution Of A Biological Problem”), statistical mechanics, etc.. But, damn it all, can a structural approach really capture the idea of independent experiments?
Let’s go a little further. Kolmogorov’s structural approach aimed to sail between the Scylla and Charbadis of interpretation. The Scylla was the open danger of philosophizing in public, especially if one cited officially deprecated reactionary philosophies such as positivism. Unfortunately, Kolmogorov was highly influenced by Richard von Mises: an empirio-critic and brother of an economic adviser of Engelbert Dollfuss. The Charbadis was the danger of simple failure: Borel’s speculations into probability theory failed to gain scientific followers (though they had a scientific audience) largely due to Borel’s lack of statistical feeling.
This point can be illustrated by a criticism of Kolmogorov by the aforementioned Richard von Mises. From his recursive system of equations, Kolmogorov derives a necessary and sufficient condition for the independence of two events A and B, simply P(AB)= P(A) P(B). But von Mises objects that the above equation could hold “by coincidence”, as demonstrated by the fair four sided die S = {1,2,3,4}, the event of rolling a number less than the mean A={1,2} and the event of rolling a prime B={2,3}. The probabilities of events A and B are both ½. The event of rolling a prime less than the mean is the joint probability AB = {2}, which has a probability of ¼. Thus the independence equation is satisfied. Yet, the probability of rolling a small number and a prime are intuitively related because the primes are “front loaded” in the natural numbers in the sense that the average gap between primes between 2 and n is proportional to the count of digits in n.
Richard von Mises argued that this and similar considerations suggest the structural approach is merely necessary, not sufficient. Further conditions, ones subject to empirio-criticism, must be also implemented. In the case considered by Airy, the condition for independence would be something like physical separation in space.
The goal of this essay is by no means an attempt at criticism of Kolmogorov’s theory of probability, not its structural core nor its measure theoretical interpretation. Even less is the goal to propagate empirio-criticism as an approach to the philosophy of science. Rather, this brief exploration of independence is of interest because independence is something between a goal - we want independent corroborations of our theories - and a fact. We shall soon see that if we can take the distinction between goals & facts as our guide, then we can come to a deeper understanding of statistical practice.
A Typical And An Atypical Backstory
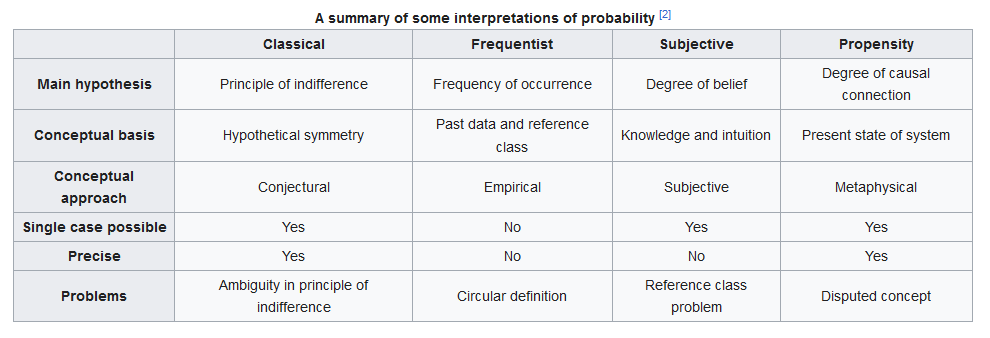
Before we can use those distinctions as our guide, I must look at a navigation method you might have seen before. On Wikipedia, that weighty authority of all knowledge, there is a fun chart of the main schools of probability. These schools have given us weighty considerations on the question of how we can and should use statistics.
This chart is original work, which can be seen from the fact that “reference class problem” is put under “subjective” but the alleged source, which seems to be mostly following Donald GIllies’s Philosophical Theories Of Probability, puts it under “frequency”. Of course the chart is far too clear and symmetrical to represent the positions of actual theorists. The alleged distinction between “inductive behavior” and “inductive inference” which caused such a row between RA Fisher and Jerzy Neyman isn’t present. But the chart is still a nice place to start, as it is a typical and thus easily shared backstory to statistical philosophizing.
“It seemed to me then, as it does now, that something new in statistics most often comes about as an offshoot from work on a scientific problem.”
George E P Box, An Accidental Statistician, “Chapter Five: An Invitation To The United States”, emphasis in original
There are other methods of organizing than this. As Box said, the problem that one is working on is something that must be accounted for. This is what is meant by being guided by fact, the facts of one’s problem.
Therefore, what must be done for the achievement of the goal of this essay is to propose another little oversimplifying view on probability. This one will be sensitive to goals and facts rather than basic philosophy. Further, rather than a list, this one will be structured as a good ol’ consulting firm 2 x 2 matrix. This matrix will be complete at the end, with the remainder of this post being a dialectic which develops the reasons why the entries are placed where they are.
Before that dialectic can start, let us map out the space we are exploring. The basic axes of the matrix are:
Method: Is the underlying action driven by compensation or inundation?
Goal: Do I want to predict something or describe something?

The dialog has thus started where Hegel recommended: mere abstract existence. The next step is the concrete process of seeing how the table will - or should have - come to be. That step will take us to the goal of a determinate table, which we can then use for ourselves.
X-Axis: Compensation vs Inundation
Any answer to the question of what we can and should do with statistics is already related to the system we are examining. We give the two rows to “compensation” and “inundation,” terms which come from Richard A. Epstein’s Theory Of Gambling And Statistical Logic. We will start at the top left and head towards the origin in defining and illustrating these terms.
X-Axis, Part 1: Compensation
Let’s start with an illustrative definition: a system with an equilibrium is driven by “compensation” if deviation from the equilibrium causes a change in the state of the system. An example of a compensatory system is a tensegrity structure where each piece has disposition to resist tension or compression, so that if one piece is disturbed the force is distributed over the whole structure so that the dispositions of each piece to resist tension/compression optimally reinforces the disposition of the whole structure to remain solid. Changes of state are capable, essentially, of compensating for the change in equilibrium.
Philosophers Karl Popper and Ian Hacking have advocated interpreting the probabilistic dispositions of a system as objective properties of the system whatever the particular outcome of the experiment may be, similar to how fragility is a disposition of glass whether the glass ever breaks or not. I will write this way as well, ignoring whether it is a façon de parler ou pas.
The simplest example of a compensative system is a system whose equilibrium is a stationary state. The stability of that state can be found by the Lypunov function method. If the state of your system is exactly described by a vector x and the dynamics ẋ are of the form ẋ=f(x), then we can define a stationary state x* as any vector such that f(x*)=0. Then a Lypunov function V is a differentiable function of the state of the system x which is positive definite except at its root at x* and V’ is negative definite. If such an arbitrary function V seems like an odd thing to chose, then just recall that by the chain rule V̇=V’ ẋ so that dx = dV/V’. The last equation says that the differential of the system’s state is proportional to the differential of any Lypunov function, with the proportionality coming from the derivative of the specific Lypunov function. Since V is positive definite except at x* its differential dV are pointing away from x*. Because V’ is negative definite, the differential dx must be pointing towards x*. Thus the dynamics must be moving towards x* and x* is stable.
Though a crude visualization, this still is a bit abstract for a blogpost. If we recall that thermodynamic stability occurs if a system has a minimum energy given its entropy, we see that the function V above is really just a generalization of the idea of energy. The system tries to minimize the generalized energy V and the minimum of the generalized energy V is at x*, thus the system is trying to get to x*. This is helpful because generalized energy has a structural rather than substantive meaning: it just is some function that satisfies some inequalities, not anything to do with the specific properties of “energy” as such.
Before moving on, I do want to mention one fun historical tidbit about Lypunov functions. Lypunov functions are only useful for stable stationary states, so they actually did not accomplish what he wanted to do (examine the stability of the periodic orbits of the solar system). As a result, the method was little used until Nicholas Minorsky, who popularized the concept of PID control, advocated their use in stability analysis for large ships. After this, use of the approach grew like wildfire, especially in the field of aircraft control.
The merely structural definition of the Lypunov function gives us something to consider when thinking about goals. Do we care about learning the substantial energy of the system as an accounting or as a function? Or does one only care about the stability of equilibrium? In the later case something structurally defined, like the generalized energy function V, will work. This is a good question, but we can put off wondering about those goals until a later section.
X-Axis, Part 2: Inundation
Compensation is relatively easy to understand, and inundation is its obverse: a system with a stable equilibrium is driven by “inundation” if deviations from an equilibrium do not cause a change in the state of the system. The well known notion of the gambler’s fallacy is based on a confusion of compensation and inundation. The equilibrium of a sequence of fair coin flips has the number of heads arbitrarily close to the number of tails, but a run of heads does not make a tail any more likely the next time the coin is flipped. Return to statistical equilibrium happens, in this case, by inundative trivialization of even long runs of heads. Essentially, without a change of state you “run out of” any given amount of deviation from equilibrium as the system adds more coin flips to its history. In fact, this inundation can be quite slow as seen by the fact that the most probable number of origin crossings of 1D random walk is zero. This is the well-known “beginner’s luck” that can take time to overcome.
On a more abstract level, consider a chaotic deterministic dynamical system with decay of correlations, such as Sinai billiards. Sinai billiards present a model where a perfect ball bounces around a frictionless billiard table with an obstacle with a smooth boundary in the center. The system is deterministic: the path of the ball is a function of its initial condition. However, it can be shown geometrically that some obstacles, including a circular one, are dispersing and cause decay of observable correlations. A good example of an observable for Sinai billiards is the “free path”, the distance between the ball’s current position and its next collision. We can use a camera to observe the free path at different moments of time and compare the observed average free path to the mean free path. The observed average free path will be normally distributed around the mean free path. But even a significant deviation from the mean free path - if by chance we happen to photograph the ball near the obstacle several times - does not cause a change in the path of the ball. The path of the ball remains a function of the ball’s initial condition. Many observations will cause the observed average free path to converge to the mean free path by inundative trivialization of chance photographs near the obstacle.
Perhaps this is all a bit abstract. A pure gambling illustration of compensation vs dispensation can be seen in the well known 18th century card game La Her. In the first round, the Dealer shuffles the deck and deals one card to themself and one for the Receiver. Epstein calls this the random play round. After this the Receiver may exchange cards with the Dealer. Next, the Dealer may draw a card off the deck. However, there is one extra rule: the position of Sir (a king) cannot change after the randomization round. If the Receiver tries to exchange for a king, then the Dealer declares “La Her” and the exchange is negated. If the Dealer tries to draw a king, then the Receiver declares “La Her” and the draw is negated. Whatever happens in the two strategic rounds, in the end the two cards of the Dealer and Receiver are compared and the winner is whoever has the higher card. The cards are ordered ace low/king high and Dealer wins ties. One might expect that because the Dealer wins ties, the game is in the Dealer’s favor. However, in fact during minimax play, this game is actually in the Receiver’s favor. By always trading low cards and trading middling cards often enough, the Receiver can make it difficult for the Dealer to have a high card. The Receiver's strategy is an inundative strategy which aims to simply outwait any streaks of kings dealt to the dealer. Because the game is simply “draw the highest card” with extra steps, it can be played very rapidly. I had my students play this game in a statistics class and record their results. It was noticeably difficult for the students to compensate for initial runs of luck, as expected by inundative strategies. Contrariwise, if the dealer aims to win by trick shuffles and/or dealing (this would be very simple for a skilled card mechanic as only the top three cards are relevant to the game), that would be a compensatory strategy as he is changing the state of the system to affect the probability of winning.
The importance of inundation vs compensation to philosophy of statistics is shown by the Ramsey/de Finetti theory of Dutch Books. The underlying assumption to this method of justifying probability axioms is that any inundative strategy that violates the probability axioms has a perfect response, which guarantees loss. Thus the presence of arbitrageurs provides a Darwinian compensatory force which flushes out inconsistent actors. For de Finetti and Jaynes, compensation is allowable structure but inundation is not.
By now it is clear that whether a system works by compensation or inundation obviously has something to do with what we can and should do with statistics. A good engineering metaphor would be the difference between measuring forces which can change an outcome and measuring viscosities which merely slow an outcome down. But what we can and should do with statistics is not a function of inundation and compensation. This is why there is a second dimension to deal with: the dimension of goals.
Y-Axis: Description vs Prediction
To reiterate: the distinction between compensation and inundation just defined and illustrated is a difference in the action of a system. The time has come to define and illustrate the x-axis distinction between the goals of the experimenter: prediction and description. These will be vital in examining what we can and should do with statistics. Having just arrived at the floor, we will carriage return back to the top and go from left to right in defining and illustrating the concepts.
Y-Axis, Part 1: Description
“The data of an experiment consist of much more than a mean and its standard deviation. In fact, not even the original observations constitute all the data. The user of the results, in order to understand them, may require also a description or reference to the method of investigation, the date, place, the duration of the test, a record of the faults discovered by the statistical controls, the amount of nonresponse, and in some cases, even the name of the observer.”
W. Edwards Deming, “On Probability As A Basis For Action”
If the goal is description, then what to do is to maximize the information content in the interpretation of data restricted by the need for the interpretation to be true. The information content of a hypothesis is what an inference tells you not only about how a system is, but also how it could be, thus Deming’s dictum above that the measurements do not exhaust the information content of the experiment. This goal is often called an “explanation” framework because the information content sought is information about the causes of the system. However, I prefer the phrase “description” because the goal - translated into a propensity framework - is to accurately describe the dispositions of a system, including the probabilistic ones.
“The old doctrine of modals is made to give place to the numerical theory of probability.”
Augustus De Morgan, Formal Logic
Now, cause is a modal concept. If the experimenter has a descriptive goal, then their use of probability and statistics are substitutes for the uses of modal logic in medieval philosophy. Where Thomas Of Aquino might use modality to judge whether or not a former prostitute can be saved, a modern crisis counselor uses statistics.
This connection between modality and statistics is as old as probability theory itself. The very term “probability” was introduced by Antoine Arnauld - or, more probably, a ghostwriting Blaise Pascal - in the last chapter of Ars Cogitandi. Arnauld - or Pascal - adopted the term from an infrascholastic debate. The so-called “probabilists” had claimed that if the application of divine law was unclear on a subject, one could follow conscience, even to the least probable possibility. One must realize that at this time “probability” means “acceptability” or “social acceptability”. Thus Gibbon can say that “Such a fact [that the Persians faithfully discharged their agreement to supply provisions to the Roman army] is probable, but undoubtedly false.”. Similarly Hume discusses not probability, but the probability of chances. We would now say “probabilities accepted by the masses”.
Catholic probabilism means that if Church doctrine can be interpreted in a way than that way is acceptable, limited only by coherence with doctrine generally. This evolved out of the Roman concept of precedent and into the modern concept of precedent. Now, probabilism is a vital part of Catholic philosophy. As Adrian Fortescue put it, Catholic “unity consists not in a mechanical uniformity of all [the Church’s] parts, but on the contrary, in their variety”. The doctrine of probabilism allows this, and cybernetics gives us good reason to understand the need of a social system to encompass variety.
However, this kind of probabilism easily leads to mere casuistry. In the 17th century, the Jansenists attempted to halt this decline with a vigorous attack in the opposite direction. The greatest of the Janesists, Pascal (the analysis is Pascal’s even if the writing is Arnauld’s), offered a complete replacement of the Jesuetical logic of “possible interpretation = permissible interpretation” with a logic of dominance in expectation.
“Those who come to this conclusion [the logic of dominance in expectation], and who follow it out in the conduct of their life, are wise and prudent, though they reason ill in all the matters of science ; and those who do not come to it, however accurate they may be in everything beside, are treated of in the Scripture as foolish and infatuated, and make a bad use of logic, of reason, and of life.”
Antoine Arnauld, Pierre Nicole (and probably Blaise Pascal), The Logic, Or The Art Of Thinking, Chapter XVI “Of the Judgment which we should make touching Future Events”
At the apex of this mode of thought, Hume defined a causal link between two objects as the presence of the second object being incompossible with the absence of the first. In other words, a counterfactual absence of the first object strictly implies the counterfactual absence of the second object. In more readable terms, the presence of the second object strictly implies the presence of the first. Hume holds this definition of to be immediate with a frequency notion of experiment: constant conjugation. Interestingly, when Hume actually defines probability, he is a strong subjectivist. As Richard Jeffrey put it: “David Hume’s skeptical answer to those questions [of the seeing the existence of objective chance] says that chances are simply projections of robust features of judgmental probabilities from our minds out into the world, whence we hear them clamoring to be let back in.”.
Ontology aside, this Hume/Pascal view does not truly capture how the probability-based information content of a hypothesis replaced the old approaches to modality in reasoning between choices. The first person to distinguish the information content of a theory and its probability was Karl Popper, who distinguished between degree of confirmation and probability in Logik Der Forschung. The dog that did not bark which shows that Popper originated this distinction is that Poincare is unaware of it, as he talks instead of maximizing the probability of a theory. One can see Gillies’ Objective Theory Of Probability, Introduction, Part vi “The Two Concept View” for more details on the history. However, the distinction between probability of a theory and the confirmation of a hypothesis is not peculiar to Popper or objectivists about chance, as an excellent Bayesian analysis can be found, for instance, in Chapter 6 of Betting On Theories by Patrick Maher.
To go deeply into the history of how descriptive statistics evolved out of modality would take up a whole book, namely Hacking’s The Emergence Of Probability. I don’t mean here to reproduce any of our illustrious predecessors' particular analyses but only to illustrate the distinction between information content of a hypothesis and probability of a theory. Maher quotes Cavendish as a typical example of scientific description: “We may therefore conclude that the electric attraction and repulsion must be inversely as some power of the distance between that of the 2 + 1/50th and that of the 2 - 1/50th, and there is no reason to think that it differs at all from the inverse duplicate ratio.”. The point estimate of 2 is not merely the center point of the interval estimate, but an assertion of conjectural (in the sense of Popper) confirmation of the hypothesis that the electrostatic force varies as the inverse square: extremely informative but with an a priori probability of zero. The pair of statements thus balance information content and probability sufficiently for Cavendish to write them.
Y-Axis, Part 2: Prediction
“Whenever I wake up with a headache, my wife tries to figure out why I got a headache: did I drink too much, did I stay up too late… I just take an aspirin.”.
George E P Box, “Rethinking Statistics For Quality Control”
So much for probability as descriptive modality. Let’s now move on to “prediction” as a goal. Returning to Arnauld/Nicole/Pascal’s we see the logic of dominance has something to do with behavior. Though the logic is a replacement for non-numerical modality, the motivation has nothing to do with the description of modal properties such as cause. In fact, it is generally true that when one says one wants “prediction” in statistics, what one really means is a guide to best behavior. The goal of an archer is to aim where the enemy is going to be, not to wonder why the enemy is running there.
Typically, one develops a parametric model of the situation. We shall return to the question of what a parameter is later, but what matters now is that parametric models reduce the space of description to the space of parameters. For Jaynes, the hallmark parametric model is a physics model which describes all relevant interactions, like the example of Cavendish above. The parameters which in the archer’s case describe the motion of the enemy, might in Box’s case be numerical descriptors of the level and distribution of pain in the head. The agent decides on a function - perhaps even a random one - of the parameters that then dictates their own behavior. The parameter values chosen then are a function - perhaps a random one - of the data observed. This allows the behavior of the parametric model to be a function of the observed data, which is desirable in certain instances.
We can now see von Mises’ critique of Kolmogorov’s structural theory of independence as implicitly predictivist, thus failing to achieve Kolmogorov’s desired neutrality. Though the fair die makes primality and smallness independent in Kolmogorov’s sense, primality and smallness could have been dependent (if for instance the die had a different number of faces). Richard von Mises’ commitment to empirio-criticism highlights descriptive rather than predictive statistics.
Kolmogorov’s predictivism, such as it is, doesn’t seem to have been intentional. But there are in fact pure predictivists in statistical philosophy: Bruno de Finetti and Jerzy Neyman for two. Probability and statistics are vital for a predictivist. As shown in the article on the game of La Her above, generally the best behavioral function of data is a random function. Further, the random function of behavior can be a random function of a random variable. This random variable can have more information than a single number. For a simple example of behavior as a random function of a random variable type use of statistics, we can check de Finetti:
“[Brier’s Rule] is used, for instance, by American meteorologists to estimate the probability of rainfall. And in the morning — so I am told — those estimates are published in newspapers and broadcasted by radio and television stations so that everybody can act accordingly. To say that the probability of rain is 60% is neither to say that ‘it will rain’ nor that ‘it will not rain’: however, in this way, everyone is in a better position to act than they would be had meteorologists sharply answered either ‘yes’ or ‘no’.”
Bruno de Finetti, Philosophical Lectures On Probability, Chapter 1: “Introductory Lectures”, Section 4: “Proper Scoring Rules”
The goal of linking behavior to data functionally differentiates predictive from descriptive statistics. Counterfactual considerations, necessary to consider cause, are ruled out. For example, it is perfectly good experimental design for a predictivist to continue an experiment until the p-value is below a certain level:
“Suppose I tell you that I tossed a coin 12 times and in the process observed 3 heads. You might make some inference about the probability of heads and whether the coin was fair. Suppose now I tell that I tossed the coin until I observed 3 heads, and I tossed it 12 times. Will you now make some different inference?”
Anonymous, “The Likelihood Principle”, Wikipedia
If behavior is a function of the data, then it is a function of the data. It is of no matter what the intention behind the experiment was. One should not make a different decision in the second case. If the readings of a probe do not go off the scale, then the statistician does not have to worry about censoring, even if they could have gone off the scale. But if one wants to describe causes, such as whether the coin is physically deformed, then the second experiment is different as the number of heads is predetermined. Cause is a modal concept after all. The second experiment is not an experiment designed to maximize the information content of the number of heads thrown.
At this point we have both distinguished the types of system one encounters and the goals that one has when encountering a system. The principle of continuity complicates all distinctions: a system may have compensative and inundative aspects and one’s goals may be a mixture of prediction and description. Of course, these distinctions are only a step on the process of figuring out how our table will come to be. The distinctions must only be sharp enough that we can arrive at a determinate table which can help us see how we can understand and use statistics.
A Matrix And Its Morals

We have defined and illustrated our axes so that the content of the matrix promised in the first section can be cashed in. Perhaps you have already been able to intuit what the contents of the matrix would be. If so, that would be a credit to the importance of the axes. But regardless of intuitive powers, it is time to examine the content of the matrix. We will start with the point (Description, Inundation) and work clockwise.
(Description, Inundation)
When a process is inundative and the goal is to describe the process, one should randomize experiments to estimate constants. There are two parts to this process: Randomization and Constants. First it must be shown how randomization as a part of design delimits our ability to make firm descriptions of inundative processes. Then parameters will be distinguished from causes and forces in order to understand why they are the correct descriptions of inundative processes.
To start with randomization, as stated in the previous section, the goal of predictive experiments is to the extent possible make behavior a function of data. Thus randomization of experiment is sheer nonsense. If one is designing an experiment to distinguish between Proper Victorian Ladies (PVL) and Time Travelers In Disguise (TTID), one could use whether the subject can truly distinguish a proper cup of tea. The subject is fed tea from an arrangement of cups. Fisher would recommend the cups be arranged randomly, perhaps drawing from a deck of well-shuffled cards and serving a hot cup on a red card and a cold cup on a black card. Let’s say one drew Red, Black, Black, Red, Red, Black and she correctly labeled each cup. You have successfully found a PVL.
Jaynes would argue that Fisher and you are merely pretending to not understand how shuffles work. A shuffle is a deterministic physical process that determines the state of the deck. The outcome is a (possibly random) function of the state of the deck and the state of the lady (PVL or TTID). Thus behavior is a (possibly random) function of the state of the deck and the state of the lady. If the goal is to determine whether to let the lady go or send her for further interviews and Red, Black, Black, Red, Red, Black gave a particularly successful behavior function, then why not keep to that pattern every time? What is the point of pretending to be bad at cards?
Of course, the answer is obvious. Fisher’s goal is not to make behavior a function of data, but to truly describe the state of the woman, PVL or TTID. The design of experiment, therefore, must be such that considerations beyond what is observed are accounted for. The description of the propensities of the system are causal and thus modal. By design, the state of the woman is not varied through the modal space of possible experiments, but the state of the deck is. The experiment, and its repetitions, is thus designed to capture that unvarying part of the experiment. The experimenter must care not only about the present data, but the counterfactual data as well.
Randomization is one side of Deming’s Dictum that observations from an experiment do not constitute all of the data. The flip of that modal coin is that one cannot make firm descriptive statements of inundative processes unless the experiment is designed before the data is collected. What is allowed to wander and what is fixed across possible worlds is a part of the description of dispositions of a system. If one simply comes across a vat of data without considering the propensities that are not expressed, then the description cannot be successful. Thus Jaynes’ perhaps successful description of Rudolf Wolf’s dice based on data is, in this view, due to his implicit modal assumptions that the dice are not varying over the 20,000 rolls but only the initial conditions of the dice upon release. This can be seen in his more detailed earlier analysis, where he considers the various physical features of the dice as “constraints”. Jaynes states boldly that his entropy approximation to chi-square tests is “combinatorial, expressing only a counting of the possibilities;” (emphasis in original) which is to say modal. This also helps show that these considerations are not dependent on frequency vs Bayesian preferences but really are motivated by goal and system.
Such is randomization, but what about constants? Partly we have already covered this: a constant is what is held still through the possible worlds described by the interpretation of an experiment. They are the propensities that characterize a system as an object in modal space, the replacement of what used to be called the essence. Constants are not necessarily a parameter or a statistic which can come from an experiment. Nonparametric methods, like the jackknife, allow us to describe a constant of a system without assuming much about the shape of the probability curve, so a constant cannot be a parameter. Similarly, a statistic like a p-value, might tell us a lot about a constant of a system, but is rarely the constant of interest itself.
It will help to see how inundation relates to constants rather than causes or forces by a famous attempt to do without inundation. In the early 19th century, it was an item of faith among scientists that highly sensitive, very controlled mircoexperiments would be virtually free of noise. In Laplace and Airy, the law of errors is motivated by the model of an enormous number of independent sources of error. This led ultimately to Maxwell’s Demon: a measuring probe smaller in scale thermal fluctuation and yet so sensitive that it could filter incoming molecules by their speed.
The point can be made by returning to the earlier example of Sinai billiards – a ball bouncing about and reflecting off the sides of an idealized billiard table with an appropriate central obstacle. As stated, the dynamics of the ball are chaotic. Let’s say that you want to get the measured average free path (i.e. distance to the next wall) as small as possible. You set up a film camera with a variable frame rate. A computer will attempt to raise the frame rate when the ball is near an obstacle and reduce it when it is far from an obstacle, which it can learn from the photographs. The first difficulty comes from the fact that if the rate changes continuously, then you have to start lowering the rate before or after striking the wall, either of which limits your ability to lower the sample average. But once your frame rate is low then you have little information about where the ball is right now, meaning you have to take a risk when raising the rate. Over time, the graph of the frame rate will look more and more like white noise. The accumulation of errors and the limited power of each success will drag the observed average free path towards the mean free path. This is the well known phenomenon of decay of correlation.
What statistics can reveal is the rate of decay of correlation, which is a function of the geometry of the system. That is, the rate of decay of correlation is constant over almost all possible initial conditions. The statistics are not for revealing the state of the system, as Maxwell assumed. That is to say, the goal is not which possible world (initial condition) you are in but what is constant through the possible worlds. Maxwell’s mistake was mistaking an inundative process for a compensatory process.
(Description, Compensation)
But what about compensatory processes? If our goal remains description, then we should still use experimental designs that take into account modality. But now the form of modal and counterfactual reasoning that we care about isn’t just stability across possible worlds but identifying causes: our measurements make what objects “necessary”?
In terms of the Sinai billiards above, we know that the obstacle causes the decay of correlations, in the sense that the presence of decay of correlations is incompossible with the absence of the obstacle. But I think analogizing the process of estimating constants with the independence of initial conditions and cause as dependence on geometry is simultaneously too unintuitive to be enlightening and too precise to be useful.
So I will switch to the place of Fisherian statistical practice and its chief descendents, biometrics and scientific quality control. The lady-tasting-tea example described above had the goal of describing causes, that is characterizing the functional dependence of dispositions of processes on conditions. The point of examining treatments of crops in factorial designs was not to find which of the treatments was the most successful in order to fast-track its adoption into agricultural practice. Instead, the goal was to figure out the causes of successful treatment which could then be improved on as treatments approached agricultural practice. We care about counterfactuals because practices are meant to be iterated, thus we care about conditions outside the experiment.
Fisher illustrated his concept of descriptive biometrics, in essence the generalization of crop experiments to nature, with the example of Johannes Schmidt and the European eel. Since ancient times, the life cycle of eels has been shrouded in mystery. Nobody had ever seen a young eel (immature eels had been misidentified as a different fish), nobody had ever seen an eel die of old age (eels have had observed life spans >150 years). A generation before Schmidt, Giovanni Grassi had shown by gross anatomy that the so-called ‘glass eel’ was in fact eel larvae and proposed that eels bred in Mediterranean bays. Schmidt took decades of vertebra and myomere measurements and found the histogram of measurements was near independent of where the eels were caught. This is unusual: fish born on opposite sides of the same lake often have distinct myomere measurements. Convinced that European eels have a single breeding ground, Schmidt began tracking that location by tracing the distribution of glass eels. As he went up the currents of the Atlantic, the average observed length of the glass eel declined. The place of reproduction - that is, the place where observed length of glass eels approached a minimum - is in the Sargasso Sea.
Schmidt and the eels are a perfect example of how statistics empower the description of the dispositions of systems that allow scientists to trace down causes. The regularity of glass eel myomere measurements is incompossible with glass eels having scattered origins, thus the single origin causes the glass eel myomere lengths (see Hume’s definition of causation above). If a glass eel wanted different myomere lengths, then it would have to have been born in a different location. And indeed this is so: American eels are born southwest of European eels.
This example also happily demonstrates the assertions that inundative and compensative processes are not perfectly distinct. Darwin taught us that the compensatory processes underlying species stability occur within a larger scale inundative process which is now called evolution. I will not speculate whether the speciation of European and American eels happened by natural selection (the accumulation of small genetic advantages) or by genetic drift of eel families in the two breeding centers. I do tend to be a follower of Sewall Wright in these matters, emphasizing multiple local maxima in the genetic fitness landscape which are reached by drift as much as hill climbing.
Before moving on, I want to draw one last moral from the biological example about the iterative nature of descriptive experiments. Fisher had a very distorted vision when describing the dispositions of one particular species he was fond of. For example, he had scientifically indefensible opinions about their propensity to form cancers late in life (his son-in-law and daughters did not share this opinion). We don’t have to listen to those wrong opinions, as we have iterated past them. Caring about iteration means worrying about counterfactuals. One of the chief advantages of the descriptive mode, the coin that rewards worrying about counterfactuals, is that a description can be wrong.
(Prediction, Compensation)
Prediction means choosing a function that relates one’s behavior to one’s data. If a process is compensative, then the data is a function of underlying forces. Unlike a description, behavior cannot be wrong=incorrect. Behavior can only be wrong=immoral. Before we come back to this point, I want to talk a bit about a group of people who thought this quadrant was the only place to be, the Bayesian revivalists. This will give us a firm footing to see the attractions and dangers of this location.
When one talks about the Bayesian revival - especially de Finetti and Jaynes - one often notes the importance of ‘determinism’ in their thinking. Jaynes and de Finetti present statistics as precise thinking in a world where all processes are compensative and all thinking is determining action. One might phrase a de Finetti flavor of determinism as saying all behavior is a function of underlying forces, but usually a random function.
The behavior is a (possibly random) function of the data, a (possibly random) function of the underlying forces. I chose to characterize the underlying facts as forces rather than constants or causes to emphasize the non-modal nature of this mode of thinking. The definition of force in modern physics is the rate of change of the quantity of motion. Newton originally defined the total force on an object as the curvature of the path of the object, with rectilinear forces treated by a limiting argument. This is a function of the actual motion of the object. Then he employed physical arguments to deduce the forces emitted by objects follow rules now called vector addition. Thus the individual forces are a function of the actual kind and actual arrangement of force emitters. But it was Euler who first developed the venomous part of Newton’s concept: forces are not merely functions of the actual process but deterministic functions. Other maximum principles in dynamics - such as the stationary action principle or the principle of least constraint - suggested modal readings, the principle of maximum effect of force suggests a modal skepticism. Counterfactuals aren’t merely alternate but also wrong.
One can make a loose link between this view and de Finetti’s Paretan fascism. For Pareto, the measured extreme inequality in post-war Italy was a function of market forces, which is to say efficiency itself. Competition at the top level of economic inequality merely engendered slow circulation of those near the same economic scale. Later, de Finetti would try to mute the extreme implications of Pareto’s theory by introducing the idea that a corporatist government could act as a mild countervailing force by considering symmetry in addition to efficiency. These considerations would lead de Finetti to join the left-libertarian Radical Party after the collapse of Fascism.
The incoherent politics of professorial weirdos aside, the goal of making one’s behavior a function of underlying forces is one we see increasingly prevalent. Social media, text and image archives, etc. are constantly generating stuff which may be euphemistically called the Data. Companies and governments want to use the Data. All the stuff Deming mentioned as useful to the quality engineer - “the date, place, the duration of the test, a record of the faults discovered by the statistical controls, the amount of nonresponse, and in some cases, even the name of the observer” - may be well outside the Data. Further, the conclusions drawn from the Data must be functionally related to the data for the conclusions to be drawn by a computer. Statisticians used to rail against cookbook statistics, now they must develop techniques far more rigid than any cookbook.
In my opinion, the rise of Bayesian Ideology is not because it has better arguments now than in the 20th century. If anything, the arguments are worse: the rise of Markov Chain Monte Carlo and related methods have made the beautiful functional structure which attracted Jaynes and de Finetti in the first place rather ugly. Instead, I believe the rise is due to the fact that Bayesian Ideology, deliberately or not, gives license to the practice of putting functions on vats of data and calling it inference.
I don’t say all this to bemoan the decadence of post-postmodern society. The issue is that behavior functions can only be wrong=immoral not wrong=incorrect. The classical theory of errors in Airy etc. conceived of uncertainty as caused by uncorrectable mistakes in measurement. But a bankrupt firm did not make mistakes, they revealed their risk preference was not to miss profits over passing their survival constraint. Nor is this a stupid inference as the recent bankruptcy of Pyrex shows. Their corporate owners clearly preferred inflated paper profits over long term survival.
(Prediction, Inundation)
“When the capital development of a country becomes a by-product of the activities of a casino, the job is likely to be ill-done.”
John Maynard Keynes. The General Theory of Employment, Interest and Money. Chapter 12, “The State of Long-Term Expectation”
Before getting into this location, let's consider the success of the simple analysis of the bankruptcy of Pyrex. The success is due to the fact that the bankruptcy of Purex reflects clear market forces. It wasn’t an inundative process of poorly chosen behavior functions. Cornell Capital bought Pyrex’s parent company, Instant Brands, and loaded it with volumes of debt that quickly became unsustainable as interest rates rose.
But what about behavior functions on inundative processes, that is to say this location? We’ve actually already discussed one, the frame rate of a camera being a function of the position of a particle in Sinai Billiards. We saw that the behavior of this function would inevitably become just white noise. Earlier, we called James Clerk Maxwell’s assumption that he could make a function of an inundative process reflect his preferences a “mistake”. The pawl of a brownian ratchet simply becomes more white noise in the system without organizing the behavior of the gear in accordance with its preferences.
The success of applying algorithms to the Data depends on the nature of the process generating the Data. Yet often in machine learning and other applications of modern statistical methods, we are not improving our knowledge of the nature of those processes. This choice is affected by market incentives. As Keynes said long ago, the predictive and inundative nature of stock market speculation means that “[t]he measure of success attained by Wall Street, regarded as an institution of which the proper social purpose is to direct new investment into the most profitable channels in terms of future yield, cannot be claimed as one of the outstanding triumphs of laissez-faire capitalism…”.
Management guru Nassim Taleb further dramatized the folly of predictive methods in an inundative process by highlighting cases where a few large outcomes dominate any sample. This is related to the case of the Sinai Billiards/Brownian Ratchet convergence of the control to white noise, but with 1/f noise. The point made here is that white noise management is already bad, even without worrying about 1/f noise.

Here is an example of white noise management in quality engineering, taken from a lecture by George E P Box. Unfortunately because this is proprietary data owned by Ford motors, it was left out of the printed version. The x-axis is time from 1972-1982 and the y-axis is the count of truly pathetic lemons, cars returned in the first six months of purchase. Each unit height represents a car with severe quality issues, a part with complete mechanical failure. You can see the frequency is pretty stable over the decade. Six month returns were rare even in the pre-consumer protection era. Some bad parts are gonna escape the factory. This is an issue for insurance, not a target for quality engineering.

Now we see the same data with Japanese manufacturing overlaid. One can see both the low initial level and the sharp drop in cars returned in the first six months of purchase. The drop, at least, is because the Japanese manufacturers took an descriptive & iterative approach to quality engineering. Interestingly, the Japanese did not try to upscale their output, but rather continued to pitch their product as practical economy cars. As consumers learned higher quality was available at lower prices, the Japanese automobiles began dominating the global market. While 1/f noise management is spectacular in failure, it was white noise management that brought American automobile manufacturers to the malaise era.
I do not mean this to be a criticism of Taleb’s beliefs, as the concept of “quality Japanese automobile” was as absurd in the 60s (in the US and Japan) as a “black swan” was to Aristotle. Rather, I agree that use of the appellation “mistake” for the application of predictive methods to inundative processes is justified.
And this time, I do say this to bemoan the decadence of post-postmodern culture.
https://www.linkedin.com/posts/anna-maria-carabelli-6386029b_goals-and-methods-in-statistics-machine-activity-7087912696058142721-SQNZ?utm_source=share&utm_medium=member_android
In his 1939 discussion on Tinbergen's method in econometrics, Keynes comes back to his 1921 Treatise on Probability's question. Is statistics or econometrics a mere description of reality or is it a probable inference (prediction) and what are the assumptions implied passing from description to prediction. Keynes's judgement is that Tinbergen's method is fallacious and inappropriate to obtain a reasonable probable inference. Note that for Keynes, a reasonable probable inference does not mean a successful prevision. In a Treatise on Probability, Keynes quotes Herodotus, saying that if one make a decision foolishly and obtain something by mere luck (by mere success), this does not make the decision less foolish.